What to expect during the Data Protection Impact Assessment (DPIA) process

How often do you contemplate if your data and details are protected by a company? It is frequently presumed important information is protected, but many times a business must abide by laws to certain regulations in order to operate ethically. One assessment provides an enhanced evaluation of businesses to ensure they are handling data properly is the Data Protection Impact Assessment or DPIA. The DPIA is a vital process used by businesses to identify and minimize the data protection risks of a project.
Previously on the blog, we discussed the importance of Third-Party Risk Management (TPRM), which included a Privacy Risk Screen Assessment involving a series of questions. If you find yourself in a situation where a Privacy Risk Screen Assessment is conducted and the answer to any of the following privacy risk screening questions is ‘yes’, an enhanced evaluation will be conducted, which could include performing a Data Protection Impact Assessment (DPIA) or Privacy Impact Assessment (PIA):
- Is the application considered a major project involving the processing of personal data and is the application considered a critical system processing personal data?
- Does the application use profiling or automated decision-making, or run algorithms to score/rate responses impacting an individual?
- Does the application process special categories of data or criminal-offense data on a large scale? Note: Large scale is defined as data processing covering more than five (5) million people or forty percent (40%) of the relevant population.
- Does the application systematically monitor a publicly accessible place on a large scale?
- Does the application use innovative technology?
- Does the application use profiling/automated decision-making (or any special categories of data) to decide whether (or not) an individual can access our services?
- Does the application conduct profiling on a large scale?
- Does the application process biometric or genetic data?
- Does the application combine, compare, or match data from multiple sources?
- Does the application process data without providing a privacy notice directly to the individual?
- Does the application process personal data in a way involving the tracking of individuals’ online/offline location/behavior?
- Does the application process children’s personal data for profiling/automated decision-making (or marketing) OR offer online services directly to children?
- Does the application process personal data resulting in a risk of physical harm in the event of a security breach?
This blog is intended to walk you step-by-step through your DPIA or PIA. The material in this blog was serviced from a collection of the best authoritative sources like the U.S. National Institute of Standards and Technology (NIST) and the U.K. Information Commissioner’s Office (ICO).
The analysis is split into the following sections:
- Description, Data, and Safeguards;
- Nature of Processing;
- Basis of Processing;
- Risks;
- Use of Personally Identifiable Information (PII); and,
- Additional Safeguards.
Description, data, and safeguards
To start, the reviewer must fully understand the system, platform, or application under review. A detailed description of the system is vital. It’s critical to understand what the system does, how it might interact with other systems, and how you use the system in your operations.

Data flow diagram
What does the flow of data look like through this system? The best way to get a visual of what data is being processed by the system is to complete a data flow diagram. The data flow diagram should identify the source, internal systems/processes, third parties, and transfer across the entire data life cycle to include:
- Creation – this is the point the data was created or sourced;
- Storage – this is the phase where the data is stored such as in a database or file;
- Processing – this is where the ‘heavy-lifting’ of the data is performed such as where the data might be calculated or formatted into useful information;
- Use/Access – to make data useful to end users, users must be able to use or access the data to perform certain tasks;
- Archival – this is the phase where data may no longer be useful; however, it may need to be saved for archiving purposes or regulatory requirements;
- Destruction – this is the ‘end-of-life’ of data where it is finally sanitized and/or destroyed.
Establish a table starting with sources, internal systems, third parties, and transfer across the top (as columns), and data life cycle elements on the left (as rows). This will help demonstrate the flow of data. Then, enter components, applications, integrations, and other elements within the ‘blocks’ and diagram the data flows.
Here is an example of a simple data flow diagram:
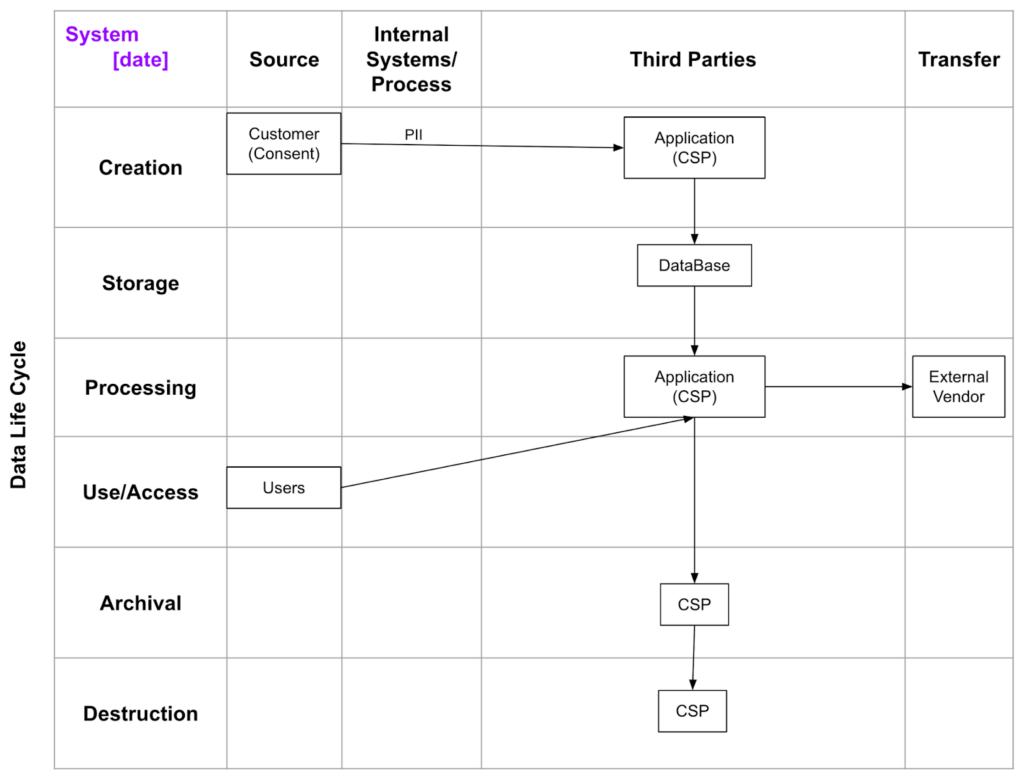
Note: It’s important to include a date on this diagram since data flows may change in future releases.
Pay special attention to some vendors in the data flow diagram. These vendors may be considered sub-processors under certain regulatory requirements like the General Data Protection Regulation (GDPR). Sub-processors may have additional requirements, contracting, or special considerations such as data processing agreements (DPAs) to utilize them.
Data
Now that the flow of data is established, the reviewer will need to figure out what type of data is transmitted throughout the system. Your industry (and other regulations) will define the types and categories of data as well as define the criticality of the data. A thorough data inventory will be performed to collect these types, categories, and criticality ratings. Some regulations like the GDPR, the Health Insurance Portability and Accountability Act (HIPAA), the California Consumer Privacy Act (CCPA), and other standards define different types as well as classifications of data. Microsoft’s Supplier Security and Privacy Assurance (SSPA) program also defines different types of data. These sources (or others) can be leveraged to define a standard by which the data can be classified.
Privacy tends to be contextual, so what may need to be kept private in one region (or use case) may not be the same in other regions (or uses). Geography will determine the regulations that must be considered in the analysis. Furthermore, almost all states and countries have regulations concerning children and the protection of children’s personal information, which must be considered as well.
Safeguards
When it comes to processing data, the different types of safeguards in place (current or proposed) are summarized. At Thoropass, we like using the control families as our topic areas offered by NIST 800-53r5 Security and Privacy Controls for Information Systems and Organizations, but you could choose any framework deemed most appropriate. A control description for each area consisting of a few sentences will be written describing how safeguards are being implemented (or how they plan to be) to protect data.
Nature of processing
The nature of processing refers to leveraging the data flow diagram to describe and document how data is collected, used, stored, and deleted. To do this, the source of the data must first be identified, as well as whether it will be shared with anyone, and if there are any high-risk activities present.
To determine the scope of processing, the reviewer will need to include the nature of the data and if it encompasses any special categories of data. They’ll also need to know how much data is being collected/used, how often, retention, individuals impacted by the data, and identify geographical areas.
It’s important the context of processing includes the relationship between the organization and individuals. Additionally, determining how much control the individual has and whether they would expect us to use the data in the way we are using it is essential. It’s also critical to identify children or any vulnerable groups as well as any prior concerns over the processing. As discussed in other blogs, AI may be considered new technology, and you should consider adopting special considerations for the current state of technology as well as current public issues in processing. As a standard, we will want to note any code of conduct we follow or certifications we have obtained related to our processing environment.
Other items that are important to understand include the purpose of processing and whether there’s any impact on individuals by processing their data. Questions to ask include:
- Why are you processing?
- What benefits are you providing to the individual, to yourself, or more broadly, to the world?
The take-home message is: There should always be a reason for processing data; as discussed in the next section, a reviewer may even be required to determine the lawful basis of processing. We may need to consult with relevant stakeholders and/or perform an analysis on the measures of compliance versus proportionality. In addition, a reviewer will be looking to see if the processing achieves the purpose set out or if there’s another way to achieve these same results.
The reason we do this is that we need to ensure data quality and minimization as well as provide individuals with certain information to support their privacy rights. It’s necessary to determine what measures are taken to ensure processors comply with regulations. If transferring information internationally, what safeguards are in place (or transfer mechanism) such as Binding Corporate Rules (BCR), Standard Contractual Clauses (SCC), Code of Conduct, Certification, or other means will need to be determined.
Basis of processing
To process any information, there needs to be a legal basis for processing. This legal basis can come from an individual giving us their specific, informed, and unambiguous consent to process their personal data for one (or more) specific purposes. We may process personal data as necessary to perform a contract the individual is a party to, or we may process personal data to comply with the legal obligations of a controller (or another sub-processor acting as a controller). Also, we may process personal data to protect the vital interest of an individual or if it is necessary to perform a task carried out in the public interest.
While processing personal data under a legitimate interest, we need to weigh the interest against the rights of the individual in addition to considering the risks of processing and other risk-mitigating measures currently (or plan to be) implemented.
Risks
Determining the processing risks leads us to assess the necessity and proportionality of the processing related to its purpose. We will conduct an assessment of the risks to the rights and freedoms of individuals as well as the risks to our company with potential violations of laws. It is essential for us to assess the risk of any potential breach of contracts and any potential reputational risks our company might face when processing the data.
Use of Personally Identifiable Information (PII)
Our team should have a pretty good understanding of how we will use any personally identifiable information (PII) at this point. We still need to determine if specific fields are storing PII within our system and if individuals can opt out of this processing, but consent to other types of processing within our system. Also, if there are any other sources of information collected from other organizations imported into our system this will be the time it will be determined. If this is the case, we need to decide why we are populating our systems with this information and whether we have the right to process this information in the first place.
In the same instance, our team will need to determine if other organizations are permitted to access the PII collected and to decipher under what authority can this information be shared. Then, roles and responsibilities over the access—both internally and externally— are assigned and the criteria used for these roles/responsibilities are determined. Leveraging our data flow diagram, working out what other systems might interconnect to share, transmit, or access the PII within our systems and the purpose of this transmission will occur.
Additional safeguards
We already drafted up a summary of the safeguards above, but it is important to include a review of the following if not previously addressed:
- Privacy policy provided to individuals;
- Controls to prevent misuse of staff having access to PII;
- Ensure the same controls are in place if more than one site is in operation;
- Identify the data protection officer or another person responsible for protecting the privacy rights of individuals along with policies/procedures establishing these responsibilities;
- Annual security and privacy training for employees as well as contractors;
- Determine the impact if data is disclosed;
- Monitor, track, and record access to PII;
- Retention periods;
- Changes required in business or technology based on the assessment performed;
- Involvement of contractors in the design/maintenance of the system along with any non-disclosure agreements (NDAs) in place; and
- Other governmental or regulatory agencies have access to our data.
Referring back to the NIST standards SP 800-144 Guidelines on Security and Privacy in Public Cloud Computing states: “Organizations are ultimately accountable for the security and privacy of data held by a cloud provider on their behalf.” You need to make sure you have appropriate contracts in place to cover responsibilities, ownership rights, notification, record retention, and exposure liability acceptance.
To maintain the privacy principle of accuracy, you must determine how to verify the accuracy of the information provided, how to keep it current, and how to provide an individual the ability to correct any inaccuracies. You’ll also need to develop processes to ensure you maintain individual rights to request, delete, opt-out, and other rights provided by specific regulations like the GDPR, HIPAA, CCPA, and others.
Final thoughts
The Data Protection Impact Assessment (DPIA) or Privacy Impact Assessment (PIA) may be required by regulations, or you may just need to understand your environment better. Performing the DPIA/PIA will give you (and your customers) a better understanding of your system and ensure you have your privacy risks identified and documented. Completing a DPIA/PIA doesn’t need to be difficult, but it may take a little time to collect the appropriate data; however, it will be time well spent.
If your organization appreciates the process shared here or if you need some assistance with your DPIA/PIA, get in touch. Thoropass experts are here to help!

Get the Guide
Founder’s Guide to Security and Compliance
Take security one step further, find out which frameworks are best for your business.


Related Posts
Stay connected
Subscribe to receive new blog articles and updates from Thoropass in your inbox.
Want to join our team?
Help Thoropass ensure that compliance never gets in the way of innovation.








.png)